#^On-Chain Vote Buying and the Rise of Dark DAOsBlockchains seem like the perfect technology for online voting. They can act as “bulletin boards,” global ledgers that were hypothesized (but never truly realized) in decades of e-voting research. Better still, blockchains enable smart contracts, which can execute on-chain elections autonomously and do away with election authorities.
Unfortunately, smart contracts aren’t just good for running elections. They’re also good for
buying them.
In this blog post, we’ll explain how and why. As an example, we’ll present a fully implemented, simple vote buying attack against the popular on-chain CarbonVote system. We’ll also discuss how trusted hardware enables even more powerful vote buying techniques that seem irresolvable even given state-of-the art cryptographic voting protocols.
Finally, we introduce a new form of attack called a
Dark DAO, not to be confused with
the “Dark DAO” the same way DAOs should not be confused with
The DAO. A Dark DAO is a decentralized cartel that buys on-chain votes opaquely (“in the dark”). We present one concrete embodiment based on Intel SGX.
In such an attack, potentially nobody, not even the DAO’s creator, can determine the DAO’s number of participants, the total amount of money pledged to the attack, or the precise logic of the attack: for example, the Dark DAO can attack a currency like Tezos, covertly collecting coins until it reaches some hidden threshold, and then telling its members to short the currency. Such a Dark DAO also has the unique ability to enforce an
information asymmetry by sending out, for example, deniable short notifications: members inside the cartel would be able to verify the short signal, but themselves could generate seemingly authentic false signals to send to outsiders.
The existence of trust-minimizing vote buying and Dark DAO primitives imply that users of all on-chain votes are vulnerable to shackling, manipulation, and control by plutocrats and coercive forces. This directly implies that all on-chain voting schemes where users can generate their own keys outside of a trusted environment inherently degrade to plutocracy, a paradigm
considered widely inferior to democratic models that such protocols attempt to approximate on-chain.
All of our schemes and attacks work regardless of identity controls, allowing user actions to be freely bought and sold. This means that schemes that rely on user-generated keys bound to user identities, like uPort or Circles, are also inherently and fundamentally vulnerable to arbitrary manipulation by plutocrats. Our schemes can also be repurposed to attack proof of stake or proof of work blockchains profitably, posing severe security implications for all blockchains.
Blockchain Voting Today
Blockchain voting schemes abound today. There’s
Votem, an end-to-end verifiable voting scheme that allows voting using mobile devices and leverages the blockchain as a place to securely post and tally the election results. Remix, the popular smart contract IDE, offers an election-administering smart contract as its training example. Yet more examples can be found
here (1),
here (2), and
here (3).
On-chain voting schemes face many challenges, privacy, latency, and scaling among them. None of these is peculiar to voting, and all will eventually be surmountable. Vote buying is a different story.
In political systems, vote buying is a pervasive and corrosive form of election fraud, with a
substantial history of undermining election integrity around the world. Sometimes, the price of a vote is a
glass of beer. Thankfully, as scholars have
observed, normal market mechanisms usually break down in vote buying schemes, for three reasons. First, vote buying is in most instances a crime. In the U.S., it’s punishable under
federal law. Second, where secret ballots are used, compliance is hard to enforce. A voter can simply drink your beer, and cast her ballot in secret however she likes. Third, even if a voter does sell their vote, there is no guarantee the counter-party will pay.
No such obstacles arise in blockchain systems. Vote buying marketplaces can be run efficiently and effectively using the same powerful tool for administering elections: smart contracts. Pseudonymity and jurisdictional complications, as always, provide (some) cover against prosecution.
In general, electronic voting schemes are in some ways harder to secure against fraud than in-person voting, and have been the
subject of general and academic interest for many years. One of the fundamental building blocks was
introduced early by David Chaum, providing anonymous mix networks for messages which could be anonymously sent by participants with receipts of inclusion. Such end-to-end verifiable voting systems, where users can check that their votes are correctly counted without sacrificing privacy, are not just the realm of theoreticians and have
actually been used for binding elections.
Later work by Benaloh and Tuinstra took issue with electronic voting schemes, noting that they offered voters a “receipt” that provided cryptographic proof of which way a given vote had been cast. This would allow for extremely efficient vote buying and coercion, clearly undesirable properties. The authors defined a new property,
receipt-freedom, to describe voting schemes where no such cryptographic proof was possible.
Further work by Juels, Catalano, and Jakobsson modeled even more powerful coercive adversaries, showing that even receipt-free schemes were not sufficient to prevent coercion and vote buying. This work defined a new security definition for voting schemes called “coercion resistance”, providing a protocol where no malicious party could successfully coerce a user in a manner that could alter election results.
In their work, Juels et. al note that “the security of our construction then relies on generation of the key pairs… by a trusted third party, or, alternatively, on an interactive, computationally secure key-generation protocol such as [24] between the players”. Such “trusted key generation”, “trusted third party”, or “trusted setup” assumptions are standard in the academic literature on coercion resistant voting schemes. Unfortunately, these requirements
do not translate to the
permissionless model, in which nodes can come and leave at any time without knowing each other a priori. This (somewhat) inherently means users generate their own keys in all such deployed systems, and cannot take advantage of trusted multiparty key generation or any centralized key service arbiter.
The blockchain space today, with predictable results, continues its tradition of ignoring decades of study and instead opts to implement the most naive possible form of voting: directly counting coin-weighted votes in a plutocratic fashion, stored in plain text on-chain. Unfortunately, it is not clear that better than such a plutocracy is achievable on-chain. We show that the permissionless model is fundamentally hostile to voting. Despite any identity or second-layer based mitigation attempts,
all permissionless voting systems (or schemes that allow users to generate their own key in an untrusted environment) are vulnerable to the same style of vote buying and coercion attacks. Many vote buying attacks can also be used for coercion, shackling users to particular voting choices by force.

That's a nice on-chain vote you've got there...
It is worth noting that the severity of bribery attacks in such protocols was
partially explored by Vitalik Buterin, though concrete mechanisms were not provided. Here we describe frictionless mechanisms useful for vote, identity buying, coercion, and coordination at a high level and discuss the implications of these particular mechanisms.
Attack Flavors
Consider a very simple voting scheme: Holders of a token get one vote per token they hold and can change their votes continually until some closing block number. We’ll use this simple “EZVote” scheme to build intuition for how our attacks can work in any on-chain voting mechanism.
There are several possible escalating attack flavors of such a scheme.
Simple Smart Contracts
The simplest low-coordination attack on on-chain voting systems involves vote buying smart contracts. Such smart contracts would simply pay users upon a provable vote for one option (or to participate in the vote, or to abstain from the vote if the vote is not anonymous). In EZVote, the smart contract could be a simple contract that holds your ERC20 until after the end date, votes yes, and returns it to you; all guarantees in the contract could be enforced by the underlying blockchain.
Such a scheme has advantages in that it requires only the trust assumptions already inherent in the underlying system, but has substantial disadvantages as well. For one, it is likely possible to publicly tell how many votes are purchased after the election is over, as this is required to handle the flow of payments in today’s smart contract systems. Also, the in-platform nature of the bribe
opens it to censorship by parties interested in preserving the health of the underlying platform/system.
Depending on the nature of the voting scheme and the underlying protocol, there may be some workarounds for these downsides. Voters could for example provide a ring signature proving to a vote buyer that they are in a list of voters who votes yes in exchange for payments. We leave the implementation details and generalizability of such schemes open.
In general, any mechanism for private smart contracts can also be used for private vote buying, solving the public nature of a smart contract based attack; cryptographically an equivalent would be the vote buyer and seller generating a secret key for funds storage via MPC together, signing two transactions: a yes vote and a transaction that released funds to the vote seller after the end of the interval. The vote seller would move funds to this key only after possessing the transaction guaranteeing a refund and payment.
This would look similar to previous work on
distributed certificate generation, adding security analysis for ensuring fairness. A naive implementation of such a scheme would encumber a users’ use of funds for other purposes during the vote (such actions are possible but require cooperation on behalf of the vote buyer; alternatively, a trusted/bonded escrow party can be used).
Trusted Hardware Buying
An even more concerning vote buying attack scheme involves the use of trusted hardware, such as
Intel SGX. Such hardware has a key feature called
remote attestation. Essentially, if Alice and Bob are communicating on the Internet, the trusted computing achieved by SGX allows Alice to prove to Bob that she is running a certain piece of code.
Trusted hardware is usually seen as a way to prove that you are running code that will not be malicious: for example, it is used
in DRM to prove that a user will not copy files that are only temporarily licensed to them, like movies. Instead, we will use trusted hardware to
shackle cryptocurrency users, paying or forcing them to use cryptocurrency wallets based on trusted hardware that
provably restrict their space of allowed behaviors (e.g. by forcing them not to vote a certain way in an election) or
allow the vote buyer trust-minimized but limited use of a user’s key (e.g. a vote buyer can force a user to sign “I Vote A”, but cannot steal or spend a user’s money).
The simplest way to deploy such technology for vote buying is to simply allow users to prove they are running a vote buyer’s malicious wallet code in exchange for a payment, secured on both sides by remote attestation technology.
In our “EZVote” example, a user would simply use a cryptocurrency wallet loaded on Intel’s SGX, running the vote buyer’s program. SGX would guarantee to the user that the wallet could never steal the user’s money (unless Intel colludes with the vote buyer). The user can provably use the wallet for everything they can do with a normal Ethereum wallet, including moving their money out (though in this case they would not be paid). The user runs their own wallet, and does not need to trust a third party for control or security of their funds. The user may not need to trust even Intel or the trusted hardware provisioner for security of their funds, as they can compile their own wallet!
When a predefined trigger condition occurs, such an SGX program would automatically vote on EZVote as the vote buyer commands, and send a receipt to the vote buyers. The vote buyer would itself be run an SGX enclave that maintains a total of all users who claim to have voted yes, and a list of their addresses. Given trust in SGX, the vote buyer need not see the full list of member users or know the total pledged amount. At the end of the vote, the vote buyer’s enclave would pay all the users who have not moved their funds or changed their vote. This would be accomplished by the enclave periodically posting a Merkle root summarizing users to be paid on-chain, providing proof to each user that they will eventually be paid. Users can claim payment after the expiry of some period by providing a proofs of inclusion in the posted Merkle history. In some particularly vulnerable vote designs, an SGX enclave can increase its efficiency by simply accumulating “yes” votes from users up-front as transactions, publishing and providing payment for them at the conclusion of the vote.
Hidden Trusted Hardware Cartels (Dark DAOs)
A more concerning attack arises when trusted hardware is combined with the idea of a
DAO, spawning a trustless organization whose goal centers on manipulating cryptocurrency votes.
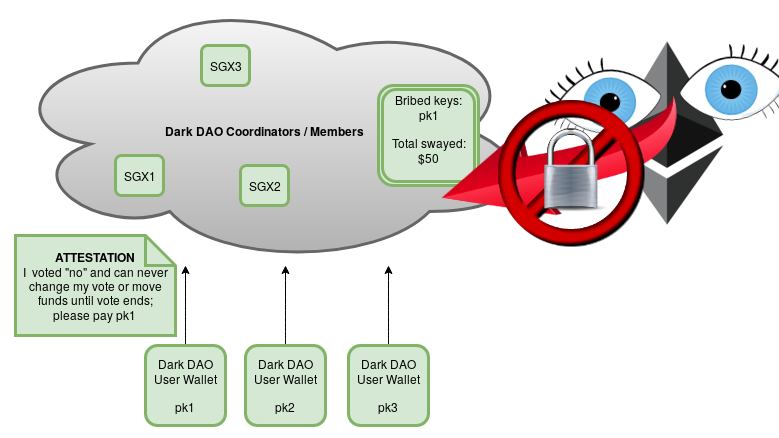
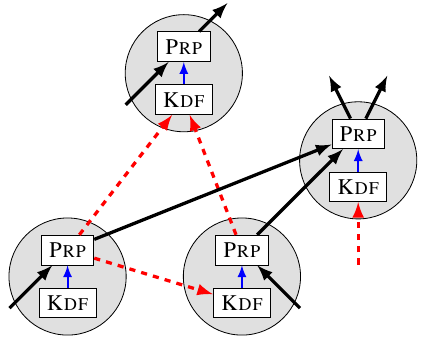
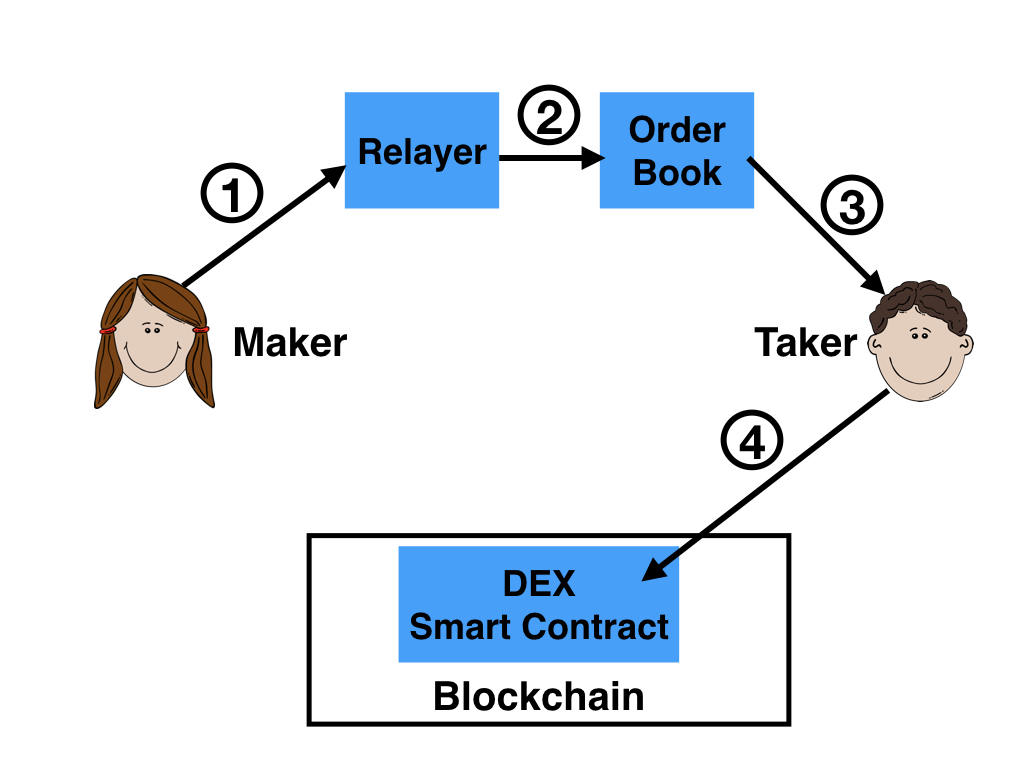
One example of a basic Dark DAO.
The figure above outlines one possible architecture. Vote buyers would support the DAO by running a network of SGX enclaves that themselves execute a consensus protocol (shown here as a dark cloud to indicate its invisibility from outside). Users would communicate with this enclave network, and supply proof that they are running a “vote buying” (e.g.) Ethereum wallet with a current balance of X coins. This “evil wallet” attests to running the attack code a vote buyer is paying for, and the vote buyer attests that they are running code guaranteed to pay the user at the end of the attack (likely in combination with a smart contract-based protocol that cryptoeconomically enforces liveness and honesty).
The vote buyers can keep track of how many total funds are pledged to vote through the system, hiding this fact from the outside world using privacy features built into SGX. Users can receive provable payouts for participating in such a system, achieving a property similar to all-or-nothing settlement in
SGX-based decentralized exchanges. Vote buyers can get a provable guarantee that clients will never issue votes that contradict their desired voting policy.
What makes such an organization
dark is that the vote buyers need not reveal how many users are participating in the system to
anybody (even potentially themselves). The system could simply accumulate users, paying users for running the attacker’s custom wallet software, until some threshold (of e.g. coins held by such software) is reached that activates an attack; in this manner, failed attempts need not be detectable. More damagingly, the individual incentives of any small users clearly point towards joining the system. If small users believe their vote doesn’t matter, they are likely to take the payoff with no perceived marginal downside. This is especially the case in on-chain votes, which are
empirically observed to have extremely low turnout. Users that don’t vote may be ideal targets for selling their votes.
Dark DAO operators can further muddy the waters by launching attacks on choices the vote buyers actually
oppose as potential false flag operations or smear campaigns; for example, Bob could run a Dark DAO working in Alice’s favor to
delegitimize the outcome of an election Bob believes he is likely to lose. The activation threshold, payout schedule, full attack strategy, number of users in the system, total amount of money pledged to the system, and more can be kept private or revealed either selectively or globally, making such DAOs ultimately tunable for structured incentive changes.
Because the organization exists off-chain, no
cartel of block producers or other system participants can detect, censor, or stop the attack.
Such a dark organization has several immediate practical drawbacks. The primary one is that for use on Intel SGX, a license would need to be granted by Intel, an unlikely event for malicious software. Furthermore, side channel, hidden software backdoor, or platform attacks in Intel's SGX or the auditing of the Dark DAO wallet could weaken the scheme, though as trusted hardware continues to advance and develop, it is highly likely the cost of such attacks will increase substantially. Eventually, we expect other trusted hardware to provide the remote attestation capabilities of Intel SGX, meaning that SGX will not be required for such an attack; this is why we use “SGX” interchangeably with “trusted hardware”. For example, remote attestation is achievable
on some Android secure processors. Our schemes work on any hardware device allowing for confidential data and remote attestation.
Attacks on Classic Schemes: CarbonVote & EIP999
To prove the efficacy of these vote buying strategies, we first look at governance-critical coinvotes performed in existing cryptocurrency systems. Perhaps the most important such vote was the
DAO CarbonVote. The operation of this vote was simple: accounts sent money to an address to vote yes, and another to vote no. Each address was a contract that logged the vote of a given address. The CarbonVote frontend then tallied the votes, and showed the net balances of all accounts that had voted yes and/or no. Later votes superseded earlier ones, allowing users to change their minds. At the end of the vote, a snapshot was taken of support and used to gauge community sentiment. This voting style is being reused for other controversial ecosystem issues, including
EIP-186.
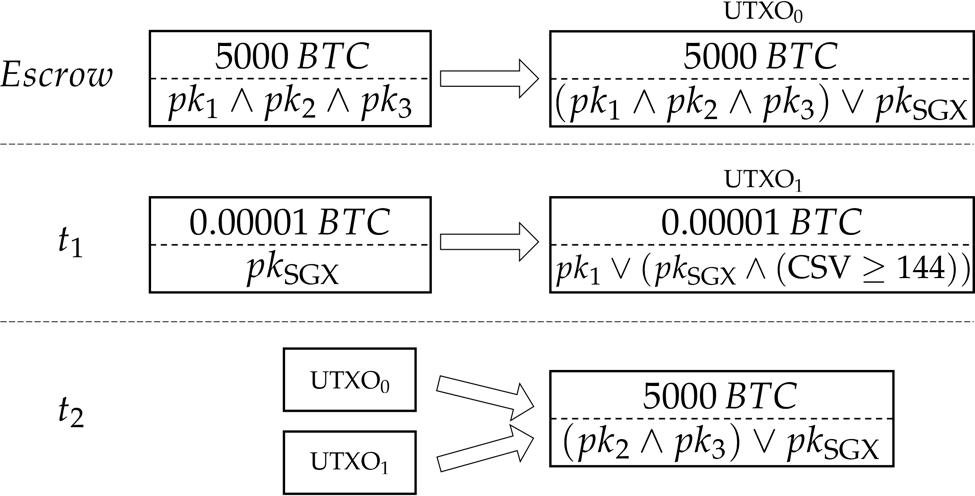
One possible trust-minimizing vote buying smart contract in this framework involves the use of escrow; users send Ether to an ERC20 token contract that holds the Ether until the end of the vote. For each Ether they deposit, users receive 1 VOTECOIN.
The contract is pre-programmed to vote yes at the end of the vote with 100% of the user Ether held. After the vote ends, each VOTECOIN token becomes fully refundable for the original Ether that created it. Users get back their original Ether, plus any bribes that vote buyers wish to pay them for this service.
We have implemented
a full, open-source proof of concept of such a contract, enabling any vote buyers to contribute funds to the contract’s BRIBEPOOL. Users can be paid out from BRIBEPOOL by temporarily locking their Ether in the contract, and can reclaim 100% of their Ether at the end of the target vote. An attack can pay vote sellers out of BRIBEPOOL upfront (once they lock the coins, the votes are guaranteed), as dividends over time, or both.
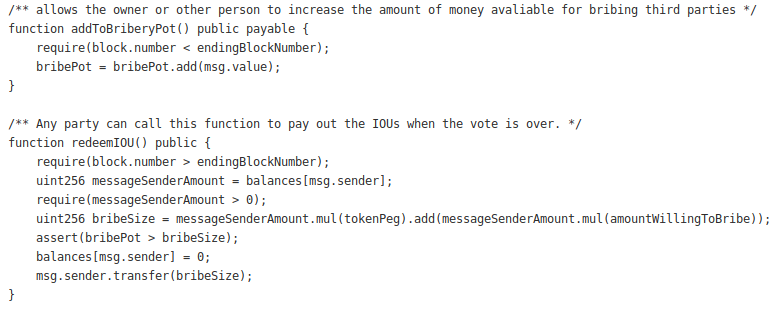
Code of the vote buying Ethereum smart contract for the DAO Carbonvote
Users can also sell their VOTECOIN after locking up their Ether, essentially making VOTECOIN a tokenized vote buying derivative. Vote sellers can then instantly unload their exposure to any risks introduced by funds lockup to parties that are indifferent to the vote’s outcome: because each ERC20 is programatically guaranteed to eventually receive all original ETH, this essentially creates a one-way-only funnel from the base asset into a derivative asset dedicated to voting a predefined way. Buyers who are uninterested in the vote's outcome should always lock their ETH if guaranteed a non-negative payoff, and essentially have an option to later unload onto other similarly uninterested buyers. If dividends from BRIBEPOOL are paid over time to VOTECOIN in addition to upfront, these derivative tokens can even be used to speculate on the success of the attack itself.
This smart contract can be simplified with the use of oracles such as
Town Crier (multiple oracles, prediction markets, etc. can be combined as well). Because the CarbonVote system publishes results including full voter logs
on Etherscan, it is relatively trivial to check which way someone has voted using any external web scraping oracles, paying them if their vote included in the final snapshot agreed with the buyers’ preference.
A Dark DAO-like model can also trivially be used. Each user simply runs a wallet that, some time after each transfer transaction, also votes the desired way on the CarbonVote (in fact this may become standard behavior for many wallets). The user is only paid if such votes are registered, so the user is incentivized to make sure this vote transaction is included on-chain. There is no way for the network to tell how many votes in a given CarbonVote are generated by such a vote buying cartel, and how many are legitimate.
Inherent in any of these schemes is the ability to minimize trust when pooling assets across multiple vote buyers; bribery smart contracts could simply allow anyone to pay into the BRIBEPOOL, and SGX networks can be architected similarly for open participation.
Some schemes, such as the
EIP999 vote, have even more severe problems. In these schemes, if a user votes twice, the later of such votes is chosen. A simple and severe attack is then to simply collect signatures on both “yes” and “no” votes from a user, spamming the chosen signature towards the end of the election period and relying on an ability to overwhelm the blockchain to ensure that most such votes persist. Alternatively, because contract deployers are able to vote for all the funds in a given contract, another attack is to simply force a user to use a contract-based wallet for the duration of the vote that is deployed by the vote buyer, who can then control the votes of all funds locked in contracts arbitrarily without custody of these funds.
Bitcoin is not immune to this problem either. Bitcoin’s community often
leans on coin-votes, and similar vote buying schemes can be applied (as either Ethereum smart contracts as in
this work, or in Dark DAO-style; Bitcoin itself does not provide native support for sufficiently rich contracts to buy votes).
Beyond Voting - Attacking Consensus
Astute readers may point out that all permissionless blockchains inherently rely on some form of permissionless voting, namely the consensus algorithm itself. Every time a blockchain comes to
global consensus on some attributes of state, what is taking place is essentially a permissionless (often coin or PoW-weighted) vote in a permissionless setting.
It is perhaps no surprise that “vote buying” has seen some exploration in these contexts. For example, smart contracts on Ethereum
can be used to attack Ethereum and other blockchains through censorship, history revision, or incentivizing empty blocks. Such attacks work directly on the proof-of-work vote itself, bribing miners according to their weighted work. There is little reason to believe that proof of stake systems would be immune to similar attacks, especially in the presence of
complex delegated voting structures whose incentives may be unclear and whose formal analysis may be incomplete or nonexistent.
A disturbing concept related to our exploration of Dark DAOs for vote buying is what we term the “Fishy DAO”, named after the
classic flash game. In this (super fun!) game, you start out as a small fish. The rules are simple; you can eat smaller competitor fish, but not fish the same size as or larger than you. You get a little bit bigger after each meal, until you eventually (if you are lucky) grow to dominate the ocean. A modern equivalent that doesn’t require Flash and adds networking is
agar.io.

It’s like Fishy, but the small fish can gang up on the bigger ones too!
A Fishy DAO would use Dark DAO-like technology as described above to do the same for blockchains. Using SGX, Fishy DAO members can receive non-transferable (DAO members can verify message authenticity, but non-members cannot tell if a message is forged) notifications when an attack threshold is reached, allowing them to short currency markets shortly before such an attack. Each blockchain Fishy DAO attack brings some profit to Fishy DAO, and the ensuing publicity of even failed attacks gives Fishy DAO notoriety with the profit-seeking but perhaps unethical (in some frameworks). If Fishy DAO fails to achieve required thresholds, Fishy DAO simply fades away and refunds its participants, potentially but not necessarily burning some amount of their money to incentivize them to recruit participation.
Fishy DAO requires Dark DAO technology, as if performed in the open with a smart contract, observable participation rates would provide market signals to the underlying blockchain’s price, rendering the attack unprofitable by allowing risk to be priced in. It is the cryptographically enforceable information asymmetry between DAO members and wider ecosystem participants that makes such an attack feasible.
Other Applications
Note that Dark DAOs have implications
far beyond the above. Consider for example a Dark DAO that aimed to profitably buy users’ basic income identities, paying up front at a small fee to receive a user’s regular basic income payments. Or a Dark DAO for getting through credit checks secured on key-based identities by leasing (with trust minimized limitations) such keys from users with good credit. Or a Dark DAO that runs an evil mining pool, provably attacking an ASIC-based proof of work cryptocurrency with an unstoppable attack pool of potentially undetectable size.
One can also imagine that with identity, there may be social safeguards against buying behavior in the identity system itself. For example, some identity systems may allow a user to show up in person to revoke or manage identities, which could socially circumvent automated technical safeguards against identity theft. There are still ways around this: the classic solution in loans is through collateral. Potentially a "bondsman" like business could also provide social guarantees of repayment through physical/legal intimidation and contract for users who cannot afford collateral. Payday loan and bail bond establishments would be ideally suited for that kind of business if such a permissionless basic income system were ever deployed alongside current market systems, at least in the US (in many other places there are likely even less savory institutions that could be willing to step in for an appropriate cut).
The coordination space of mechanisms in blockchains is large, and the environment hostile. All voting or financially incentivized identity-based schemes should be very careful to consider the implications of the underlying permissionless model on long-term viability, scalability, and security.
Core Insights
Maybe you are an academic skimming this article, or maybe an interested user wondering exactly what this all means. There are a few interesting and very surprising (in the research literature) insights to be gleaned from our thought experiments above:
- Permissionless e-voting *requires* trusted hardware. Perhaps the most surprising result is this one. In any model where users are able to generate their own keys (required for the "permissionless" model), low coordination bribery attacks are inherently possible using trusted hardware as described above. The only defense from this is more trusted hardware: to know a user has access to their own key material (and therefore cannot be coerced or bribed), some assurance is required that the user has seen their key. Trusted hardware can do this through either a trusted hardware token setup channel (similar to governments using electronic votes for democracy), or through an SGX-based system that guarantees that any voters have had their key material revealed to whatever operating system they are running. This inherently implements the kind of trusted setup/generation assumptions academic e-voting schemes have been using for years. Clearly, in the presence of trusted hardware, such assumptions are required for any vote, and votes can be provably bought/sold/bribed/coerced with low friction in the absence of this assumption, a surprising result with severe implications in on-chain voting.
- The space of voting and coordination mechanisms is massive and extremely poorly understood. As explored through concrete examples on how to handle e.g. smart contracts voting and vote changes on Ethereum, it is clear that a wide range of design decisions fundamentally alters the incentive structures of voting mechanisms (we explore these in Appendix A below). These mechanisms are extremely complex, and can have their incentive structures altered by other coordination mechanisms like smart contracts and trusted hardware-based DAOs. The properties of these mechanisms, especially when multiple such mechanisms interact or are actively attacked by resourced actors, is extremely poorly understood. No mechanism of this kind should be used for direct on-chain decision making any time soon.
- The same class of vote buying attacks works for any identity system. These attacks are not only for votes. Imagine an identity system which gives users the right to a basic income, paid weekly. I can simply pay you cash up front to buy your identity and therefore share of income for the next year, and indeed should do so if my time value of money is lower than yours (as wealth asymmetries often imply). This is the case for any system involving identity: with relatively low trust, the behavior of user identities can be constrained, and such constraints can be bought and sold on the open market. This has severe and fundamental impact on the robustness of any on-chain economic mechanism with a permissionless identity component.
- On-chain voting fundamentally degrades to plutocracy. Voting and democracy fundamentally relies on secret ballot assumptions and identity infrastructure that exists only in meatspace. These assumptions do not carry over to blockchains, making the same techniques fundamentally broken in a permissionless model. External, even trusted, identity systems again do not address the issue as long as users can generate their own keys (see above).
- Hard fork-based governance provides users the only exit from such plutocracy. A natural question to ask given the above is whether we've already arrived at plutocracy. The answer is "probably not". There is some evidence that the ad-hoc, informal, fork-based governance models that govern blockchains like Bitcoin and Ethereum actually provide robust user rights protection. In this model, any upgrades must offer the user an active choice, and groups of users can choose to opt out if disagreeing with rule changes. On-chain voting, on the other hand, creates a natural default that, especially when combined with inattentive or uncaring users, can create strong anti-fork inertia around staying with the coinvote.
- Multiple blockchains interacting can break the incentive compatibility of all chains. Importantly and critically, the Fishy DAO style attack we've explored shows that multiple competing blockchains has the ability to fundamentally affect the internal equilibrium of all such chains. For example, in a world with only one smart contract system, Ethereum, internal incentives may lead to stable equilibria. With two players, and the underdog incentivized to launch a bribery attack to destroy their competitors, such equilibria can be disrupted, changed, and destroyed. A critical and surprisingly underexplored open area of research is modelling the macroeconomics of competition between blockchains, gaining insight into how exactly such internal equilibria can fail. We find it intuitively ~certain that critical black swan events are currently lurking in the complexity of blockchain governance and interoperability.
Obviously, these all require further exploration, tweaking, and proof. But I think we have at least provided some intuition for why we believe the above to hold in a principled analysis framework.
Conclusion
The trend of on-chain voting in blockchain is inspired by the long human tradition of voting and democracy. Unfortunately, safeguards available to us in the real world, such as enforced private/deniable voting, approximate identity controls, and attributability of widespread fraud are simply not available in the permissionless model. When public keys generated by the users themselves are used, on-chain voting is not able to provide guarantees about these users having any anti-coercion guarantees. Elaborate voting schemes do little to quell (and in many cases indeed aggravate) the problem. On-chain voting schemes further complicate incentives, creating an unstable and tangled mess of incentives that can at any time be altered by trustless smart contract or Dark DAO-style vote buying, bribery, and griefing schemes.
We encourage the community to be highly skeptical of the outcome of any on-chain vote, specifically as on-chain voting becomes an ever-important staple of decision making in blockchain systems. The space for designing mechanisms that enable new forms of abuse with lower-than-ever coordination costs supports the position that votes should be used for signals not decisions, and that a wide variety of voting mechanisms should fill such roles. Without such safeguards, it remains possible that all on-chain voting systems degenerate into plutocracy through direct vote and participation buying and even vote tokenization.
Such attacks have substantial implications for the future security of all blockchain-based voting systems.
Acknowledgements
We’d like to thank
Patrick McCorry for his helpful, thorough feedback throughout the lifecycle of this post, and pioneering work in vote buying and on-chain voting systems.
We also thank
Omer Shlomovits and
István András Seres for their helpful comments on
early access versions of this post.
Appendix A - On-chain Vote Differentiators
We notice several distinguishing factors in on-chain voting systems:
- Vote-changing ability: If users cannot change their vote, trivial vote buying is possible with any method that provides a cryptographically checkable receipt. A smart contract can simply bribe users up-front for their vote, which can now never be changed. Most schemes, however, allow users to change or withdraw their votes, meaning bribery needs some continuous time component (or to be done after a snapshot of the vote is taken). Exponentially increasing payouts over time provide an interesting solution that discourages coin movement and encourages long-term signaling, and payout bonuses at vote completion are tools potential vote-buyers can use to create viable vote buying schemes when users are allowed to change votes.
- Smart contract/delegated voting: Who gets to vote for funds stored by smart contracts? This is an open question that plagues existing designs; the original CarbonVote allows any contract that can call a function to vote and later change its mind. The EIP999 vote allows contract deployers to vote on behalf of contracts, a decision widely criticized as being intended to sway vote outcomes. However, neither design seems ideal. Indeed, it seems intuitively difficult for a single design to capture all the custody nuances in smart contracts fairly: funds-holding smart contracts can range from simple multisignature accounts to complex decentralized organizations with their own revenue streams and inter-contract financial relationships. Which of these coins have voting rights, and how to fairly assign these rights remains an entirely unexplored philosophical requirement for building a fair on-chain voting system. Forcing contract authors to provide explicit functionality is likely also insufficient, as the very requirements of this functionality can in the future change without backwards compatibility (through either chain voting or forks).
- Deniability/provability: All of the schemes explored in this article have features which make them particularly amenable to vote buying: they provide the voter with some form of trust-minimizing cryptographic proof of their vote, either through an on-chain log, a secured web interface, or a smart contract’s state. Such schemes are particularly vulnerable to vote buying, as they make it easy for smart contract-style logic to validate votes. Some traditional e-voting schemes in academic literature provide a property known as coercion resistance. In these schemes, a user is able to change their mind post-coercion using the key they use for voting, and votes are not attributable to individual users. In general, the privacy concerns of having votes associated with any kind of long-standing identity, especially those holding coins, are severe. Such concerns would be completely disqualifying for any serious voting systems in the real world, and probably should be disqualifying in all thoughtful on-chain voting design criteria.